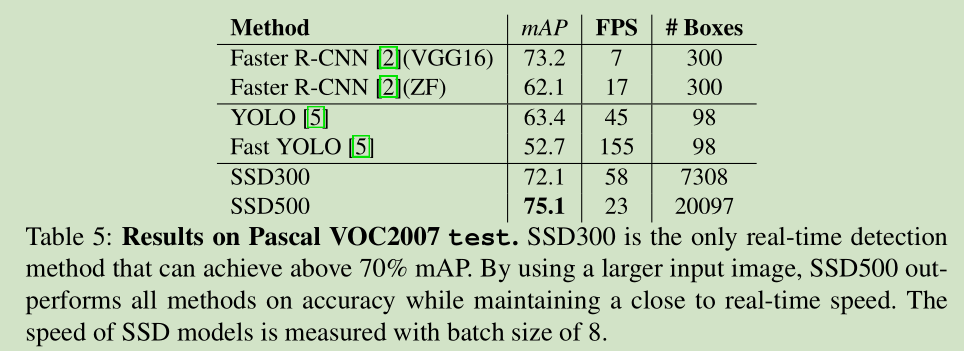
SSD: Single Shot MultiBox Detector SSD 一句话就是速度快,效果好! 第一版 8 Dec 2015,第二版是30 Mar 2016 主要改进是内容更加详实,实验更加丰富,尤其是和 Faster R-CNN 和 YOLO 做了对比,其优势比较明显。 SSD把 候选区域提取步骤取消了。The fundamental improvement in speed comes from eliminating bounding box proposals and the subsequent pixel or feature resampling stage. For 300 × 300 input, SSD achieves 72.1% mAP on VOC2007 test at 58 FPS on a Nvidia TitanX and for 500×500 input , SSD achieves 75.1% mAP, outperforming a comparable state of the art Faster R-CNN model. 开源代码
2 The Single Shot Detector (SSD)
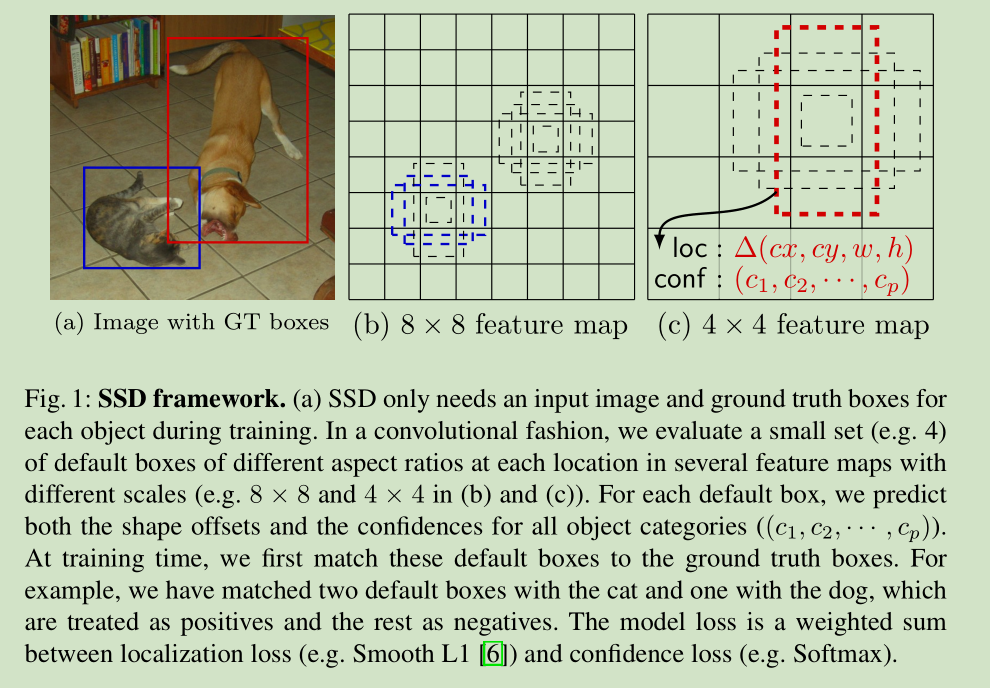
2.1 Model SSD网络包括两个部分,前面的是基础网络,就是用于图像分类的标准网络,但是把涉及到分类的层全部裁掉,后面的网络是我们自己的设计的,主要实现以下目标: Multi-scale feature maps for detection:我们加入卷积特征层,得到不同尺度的特征层,从而实现多尺度目标检测 ,用于不同尺度的目标预测的卷积模型是不同的。
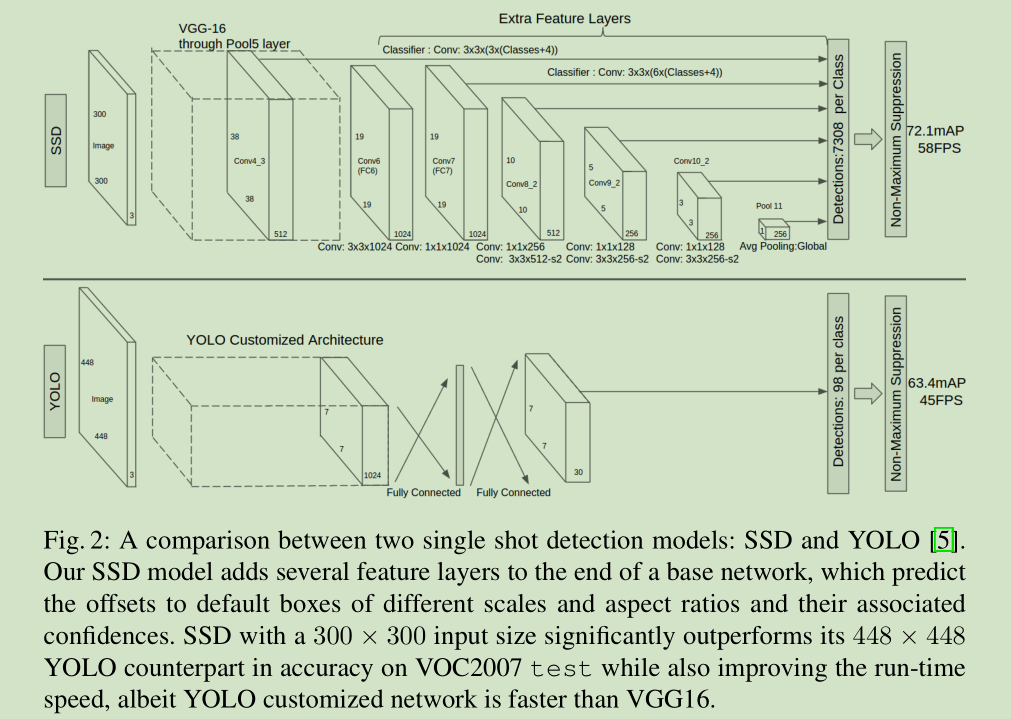
Convolutional predictors for detection 对于每个添加的特征层,我们使用一组卷积滤波器,可以得到一组固定数目的目标检测的预测 。对于一个尺寸为m*n,p通道的特征层,我们使用一个 3*3*p 的小核作为一个基础元素来预测一个可能检测的信息(类别信息,位置信息)
Default boxes and aspect ratios 在 Faster R-CNN中使用了 anchor boxes 实现不同大小和宽高比的物体提取 ,本文使用了类似的一组 default bounding boxes,和 Faster R-CNN 主要区别在于,我们是在不同尺度的特征层上进行 这些default bounding boxes 检测运算的。
2.2 Training 训练SSD和训练一个使用候选区域及池化的标准检测器最大不同之处在于,真值信息需要被赋予一组固定集合检测输出中某一个特定输出。当这个赋值确定之后,损失函数和后向传播就可以被端到端的应用。
Matching strategy 在训练时,我们需要建立真值和 default boxes的对应关系。对于每个真值,我们选择不同位置、宽高比、尺度的 default boxes 与之匹配,选择重合最大的 default boxe。这个和 original MultiBox [7] 是相似的。但是不同于 MultiBox,我们match default boxes to any ground truth with jaccard overlap higher than a threshold(0.5),这么做是为了简化学习问题
Training objective SSD的训练目标函数是从 MultiBox 目标函数衍生出来的,但是被拓展到多类别问题。
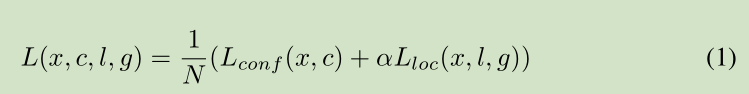
Choosing scales and aspect ratios for default boxes 主要是利用了不同尺寸的特征层,在文献【10,11,12】中已经使用过,例如是 Hypercolumn。图1 给出了一个示例,不同大小目标对应不同尺度
Hard negative mining 这里我们将正负样本比保持为 3:1
Data augmentation 为了使得模型适应各种情况,我们做了训练数据扩展
3 Experimental Results Base network 使用 VGG16